from langfree.runs import get_recent_runs
runs = get_recent_runs(last_n_days=3, limit=5)Fetching runs with this filter: and(eq(status, "success"), gte(start_time, "11/03/2023"), lte(start_time, "11/07/2023"))ChatOpenAI runs from LangSmith.
langfree helps you extract, transform and curate ChatOpenAI runs from traces stored in LangSmith, which can be used for fine-tuning and evaluation.

Langchain has native tracing support that allows you to log runs. This data is a valuable resource for fine-tuning and evaluation. LangSmith is a commercial application that facilitates some of these tasks.
However, LangSmith may not suit everyone’s needs. It is often desirable to buid your own data inspection and curation infrastructure:
One pattern I noticed is that great AI researchers are willing to manually inspect lots of data. And more than that, they build infrastructure that allows them to manually inspect data quickly. Though not glamorous, manually examining data gives valuable intuitions about the problem. The canonical example here is Andrej Karpathy doing the ImageNet 2000-way classification task himself.
langfree helps you export data from LangSmith and build data curation tools. By building you own data curation tools, so you can add features you need like:
Furthermore,langfree provides a handful of Shiny for Python components ease the process of creating data curation applications.
pip install langfreeThe runs module contains some utilities to quickly get runs. We can get the recent runs from langsmith like so:
from langfree.runs import get_recent_runs
runs = get_recent_runs(last_n_days=3, limit=5)Fetching runs with this filter: and(eq(status, "success"), gte(start_time, "11/03/2023"), lte(start_time, "11/07/2023"))print(f'Fetched {len(list(runs))} runs')Fetched 5 runsThere are other utlities like get_runs_by_commit if you are tagging runs by commit SHA. You can also use the langsmith sdk to get runs.
ChatRecordSet parses the LangChain run in the following ways:
ChatOpenAI) in the chain where the run resides. You are often interested in the last call to the language model in the chain when curating data for fine tuning.from langfree.chatrecord import ChatRecordSet
llm_data = ChatRecordSet.from_runs(runs)Inspect Data
llm_data[0].child_run.inputs[0]{'role': 'system',
'content': "You are a helpful documentation Q&A assistant, trained to answer questions from LangSmith's documentation. LangChain is a framework for building applications using large language models.\nThe current time is 2023-09-05 16:49:07.308007.\n\nRelevant documents will be retrieved in the following messages."}llm_data[0].child_run.output{'role': 'assistant',
'content': "Currently, LangSmith does not support project migration between organizations. However, you can manually imitate this process by reading and writing runs and datasets using the SDK. Here's an example of exporting runs:\n\n1. Read the runs from the source organization using the SDK.\n2. Write the runs to the destination organization using the SDK.\n\nBy following this process, you can transfer your runs from one organization to another. However, it may be faster to create a new project within your destination organization and start fresh.\n\nIf you have any further questions or need assistance, please reach out to us at support@langchain.dev."}You can also see a flattened version of the input and the output
print(llm_data[0].flat_input[:200])### System
You are a helpful documentation Q&A assistant, trained to answer questions from LangSmith's documentation. LangChain is a framework for building applications using large language models.
Tprint(llm_data[0].flat_output[:200])### Assistant
Currently, LangSmith does not support project migration between organizations. However, you can manually imitate this process by reading and writing runs and datasets using the SDK. HerPerform data augmentation by rephrasing the first human input. Here is the first human input before data augmentation:
run = llm_data[0].child_run
[x for x in run.inputs if x['role'] == 'user'][{'role': 'user',
'content': 'How do I move my project between organizations?'}]Update the inputs:
from langfree.transform import reword_input
run.inputs = reword_input(run.inputs)rephrased input as: How can I transfer my project from one organization to another?Check that the inputs are updated correctly:
[x for x in run.inputs if x['role'] == 'user'][{'role': 'user',
'content': 'How can I transfer my project from one organization to another?'}]You can also call .to_dicts() to convert llm_data to a list of dicts that can be converted to jsonl for fine-tuning OpenAI models.
llm_dicts = llm_data.to_dicts()
print(llm_dicts[0].keys(), len(llm_dicts))dict_keys(['functions', 'messages']) 5You can use write_to_jsonl and validate_jsonl to help write this data to .jsonl and validate it.
The previous steps showed you how to collect and transform your data from LangChain runs. Next, you can feed this data into a tool to help you curate this data for fine tuning.
To learn how to run and customize this kind of tool, read the tutorial. langfree can help you quickly build something that looks like this:
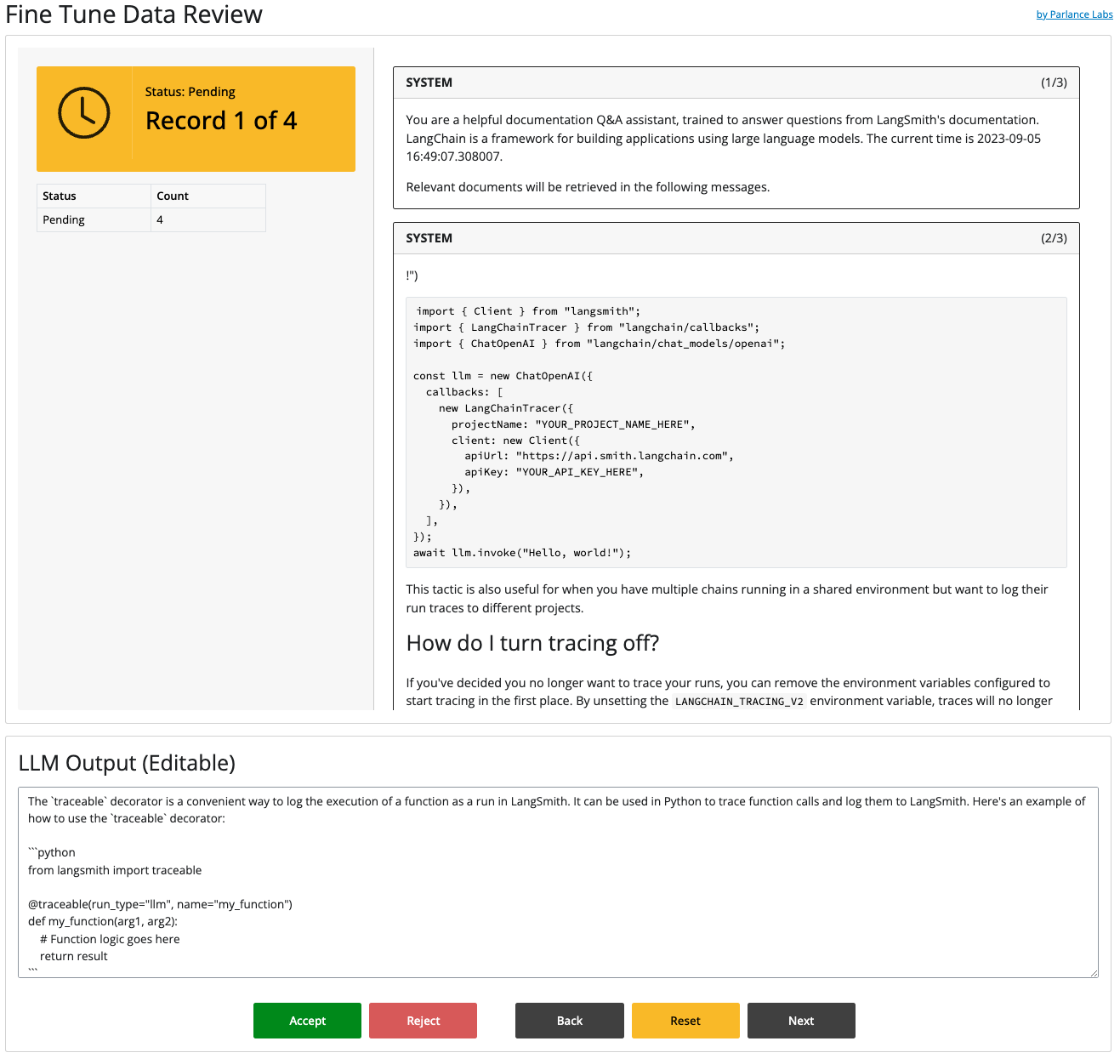
We don’t use LangChain. Can we still use something from this library? No, not directly. However, we recommend looking at how the Shiny for Python App works so you can adapt it towards your own use cases.
Why did you use Shiny For Python? Python has many great front-end libraries like Gradio, Streamlit, Panel and others. However, we liked Shiny For Python the best, because of its reactive model, modularity, strong integration with Quarto, and WASM support. You can read more about it here.
Does this only work with runs from LangChain/LangSmith? Yes, langfree has only been tested with LangChain runs that have been logged toLangSmith, however we suspect that you could log your traces elsewhere and pull them in a similar manner.
Does this only work with ChatOpenAI runs? A: Yes, langfree is opinionated and only works with runs that use chat models from OpenAI (which use ChatOpenAI in LangChain). We didn’t want to over-generalize this tool too quickly and started with the most popular combination of things.
Do you offer support?: These tools are free and licensed under Apache 2.0. If you want support or customization, feel free to reach out to us.
This library was created with nbdev. See Contributing.md for further guidelines.